
In the previous post, we explored how the DeepSeek team utilized an HPC codesign approach. By enhancing both the model architecture and the training framework, they were able to train DeepSeek models effectively while using fewer resources. In this article, we will delve into the innovative techniques they employed in their training methodology.
Large Scale Reinforcement Learning
DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation. This computation ranges from generating hundreds to thousands of reasoning tokens, allowing the model to explore and refine its thought processes in greater depth
One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously.
– DeepSeek-R1 paper
One of the primary innovations from the DeepSeek team is the application of direct, large-scale unsupervised Reinforcement Learning (RL) for LLM training. Their research demonstrates that the use of RL naturally enhanced the model’s reasoning abilities.
Reinforcement learning (RL) has been used extensively in multiple domains, including robotics. It is a machine learning technique where the model learns to make decisions based on feedback. Desired behaviors are rewarded, and undesired behaviors are punished.
At a high level, the RL learning process involves an agent (the model being trained) and an interpreter model. The interpreter model reviews the agent’s results and takes input from the environment to determine a reward to apply to the model.

RL enables an agent to learn optimal strategies in complex environments by interacting directly with the environment and focusing on maximizing long-term rewards. This makes the model particularly adept at handling dynamic, uncertain situations where immediate feedback may not be available. In contrast, traditional machine learning methods often rely on pre-labeled datasets. RL essentially helps the model learn by experiencing the consequences of its actions and adapting its behavior to achieve the best possible outcome.
Existing Proximal Policy Optimization (PPO)
While there are many reinforcement learning algorithms, PPO, introduced by OpenAI in 2017, has been the default RL algorithm since 2018.
PPO’s inner workings
As shown in Fig 2 below, PPO uses four models:
-
Policy Model: This is the LLM model being tuned.
-
Reference Model: This is identical to the policy model, but it’s frozen and used to reduce model divergence.
-
Reward Model: This is a pre-trained model that evaluates the reward for generated text.
-
Value Model: This is trained as part of the RL process to estimate the long-term value for the generated output.
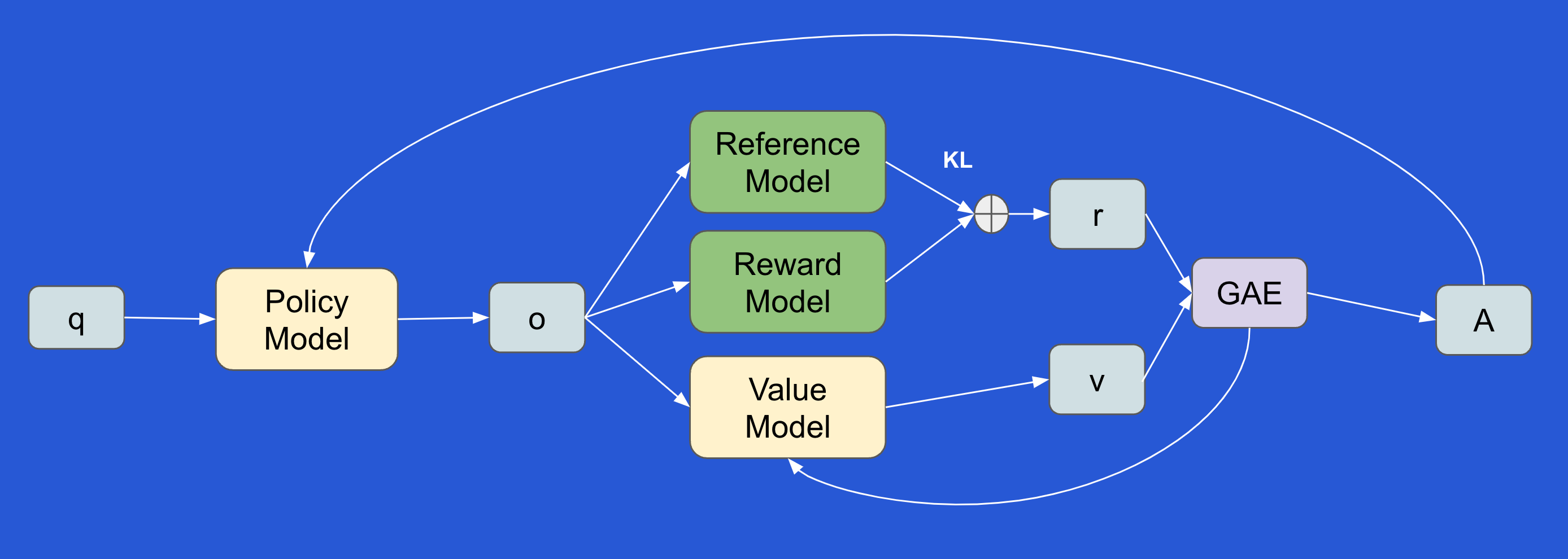
The PPO Process
-
A query (q) is submitted to the policy model, which generates an output (o).
-
The reward model computes a reward (r) for the output.
-
The value model estimates a value (v) for the output.
-
The Generalized Advantage Estimation (GAE) function combines r, v, and the reference model output to estimate the advantage (A).
-
The advantage is then used to update the policy model weights.
Key Takeaway
PPO’s use of four models makes it compute-intensive, presenting challenges for large-scale RL implementations.
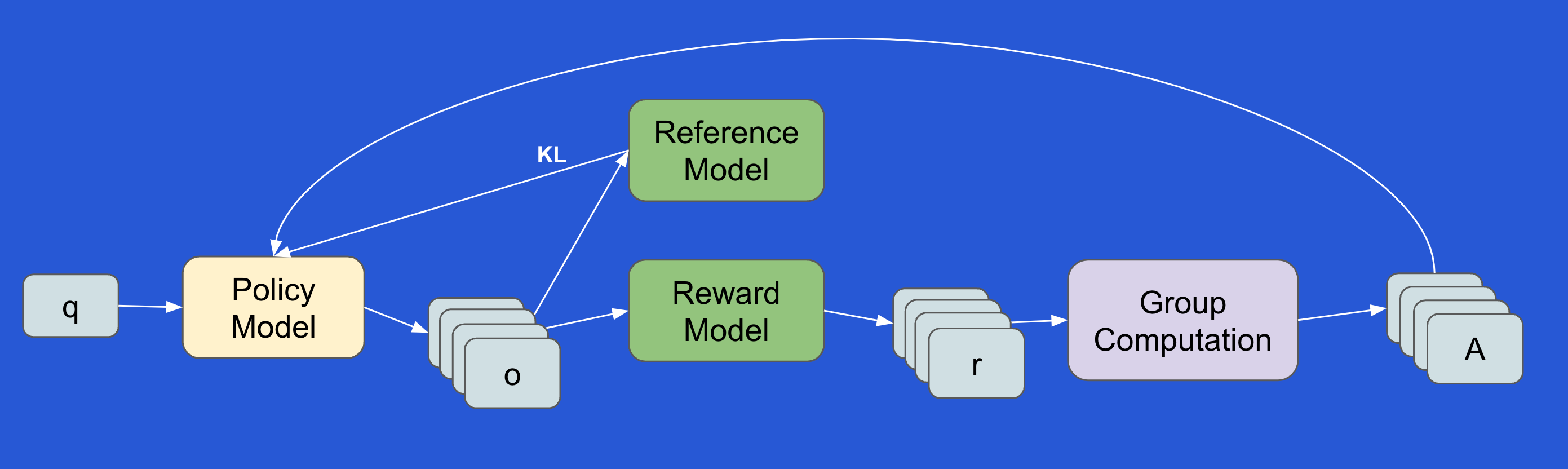
DeepSeek’s Group Relative Policy Optimization (GRPO)
The DeepSeek was able to address the scaling challenges by simplifying two key parts of PPO:
-
replacing a learnt value model with a simpler rules based reward computation
-
simplified KL regularization
With these optimizations, the team was able to use RL at scale during pre-training of the model.
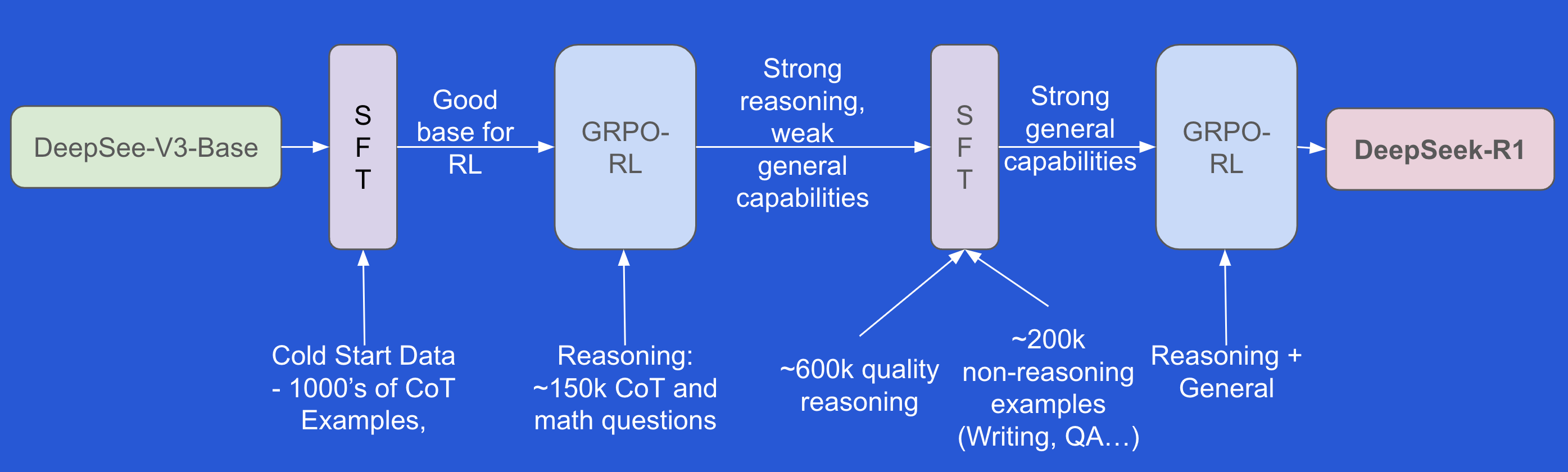
Four Stage Training Pipeline
The use of large-scale unsupervised RL led to the development of a strong reasoning model. However, this model encountered challenges related to readability, language mixing, and generalization to non-reasoning tasks. To address these issues, the team devised a new four-stage training pipeline that incorporates two supervised fine-tuning (SFT) and two reinforcement learning (RL) stages.
The initial SFT stage utilizes high-quality cold start data to stabilize the subsequent RL step, which in turn enhances the model’s reasoning capabilities. This is followed by another SFT stage that employs rejection sampling to further strengthen the model and includes non-reasoning examples to improve its performance on non-reasoning tasks.
The final RL stage incorporates more general tasks to align the model with human expectations and includes a reward for readability and single language usage in its policy optimization step.
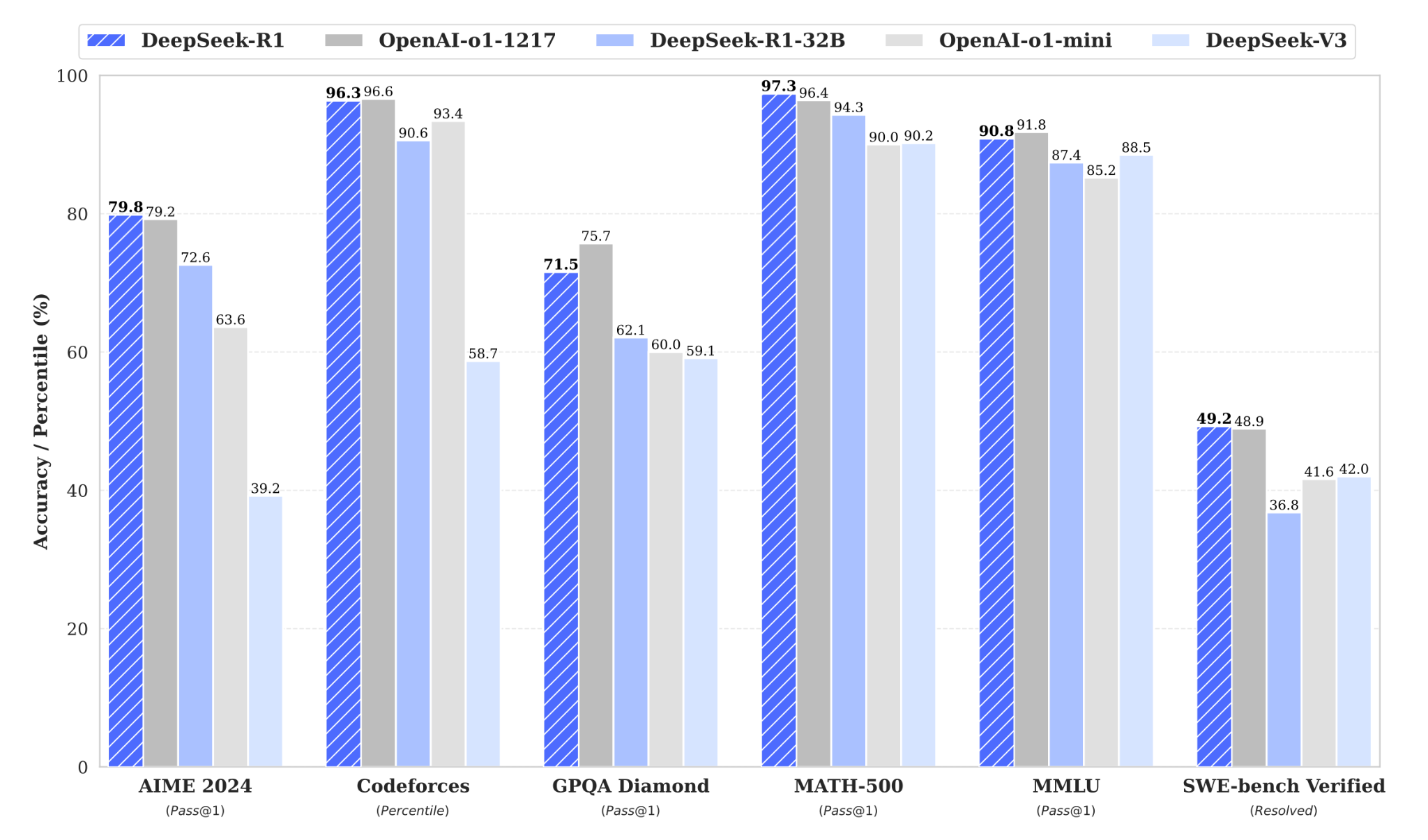
DeepSeek-R1 Results
The DeepSeek-R1 model showcased impressive results, with the team summarizing their findings as follows:
-
DeepSeek-R1’s performance was on par with OpenAI-o1-1217 on multiple tasks.
-
The model’s strong document analysis capabilities were evident in its performance on FRAMES, a long-context-dependent QA task.
-
DeepSeek-R1 displayed strong instruction-following capabilities, based on impressive results on the IF-Eval benchmark.
-
The model’s strengths in writing tasks and open-domain question answering were highlighted by good performance with AlpacaEval2.0 and ArenaHard.
-
DeepSeek-R1’s performance on the Chinese SimpleQA benchmark was worse than DeepSeek-V3 due to the addition of Safety RL to control output (censorship?).
-
Large-scale reinforcement learning was highly effective for STEM-related questions with clear and specific answers.
-
Reasoning models were generally better at handling fact-based queries.
-
Reasoning tasks
-
79.8% Pass@1 on AIME 2024
-
97.3% on MATH-500
-
2,029 Elo rating on Codeforces
-
-
Knowledge
-
90.8% on MMLU
-
84.0% on MMLU-Pro
-
71.5% on GPQA Diamond
-
-
Others
-
87.6% on AlpacaEval 2.0
-
92.3% on ArenaHard
-
Model Distillation
Distillation Creates Smaller, More Efficient Models
The DeepSeek team found that smaller, denser models trained on data from the larger R1 model, through a process called distillation, performed very well on benchmarks. This finding can help create smaller, more efficient models in the industry.
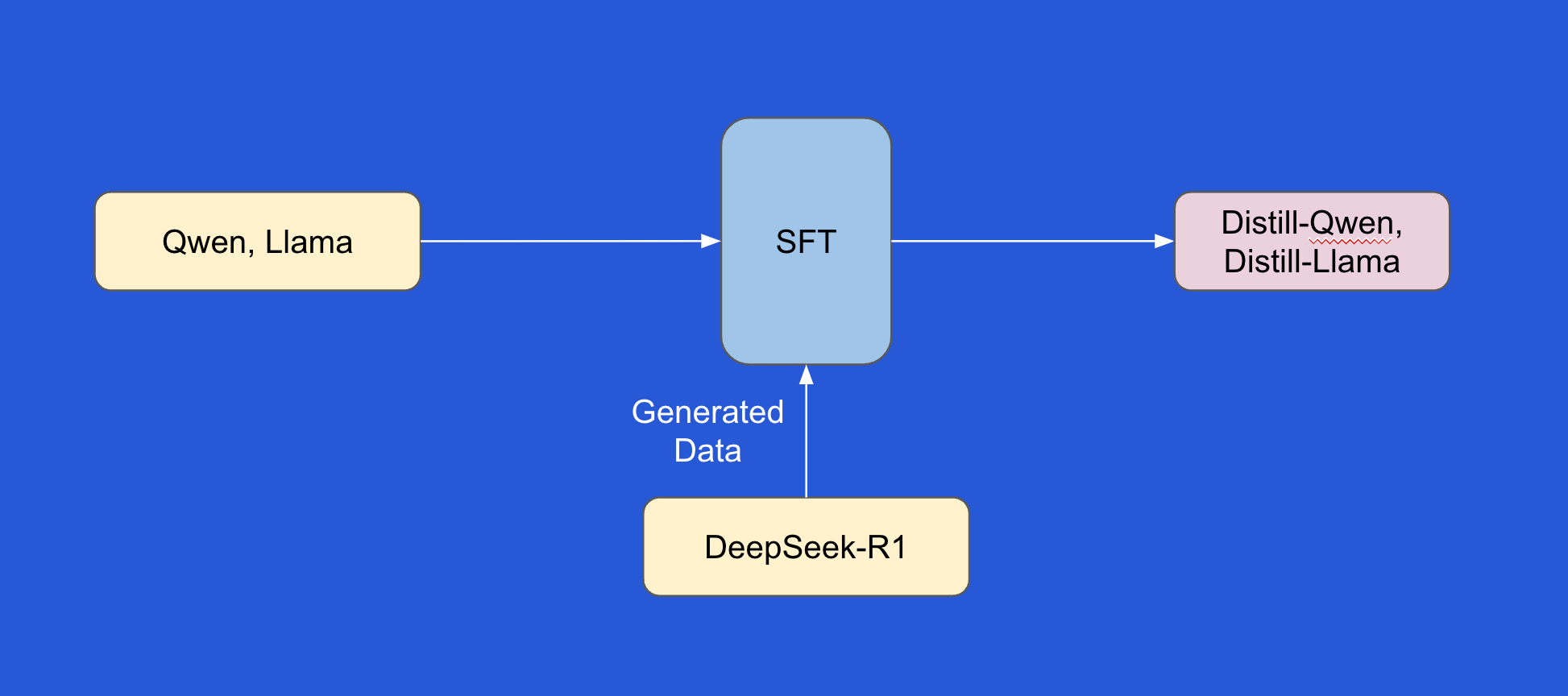
Six Distilled Models Created
Using the Llama and Qwen models, the team created six distilled models:
-
Distill-Qwen-1.5B (1.5 billion parameters)
-
Distill-Qwen-7B (7 billion parameters)
-
Distill-Qwen-14B (14 billion parameters)
-
Distill-Qwen-32B (32 billion parameters)
-
Distill-Llama-8B (8 billion parameters)
-
Distill-Llama-70B (70 billion parameters)
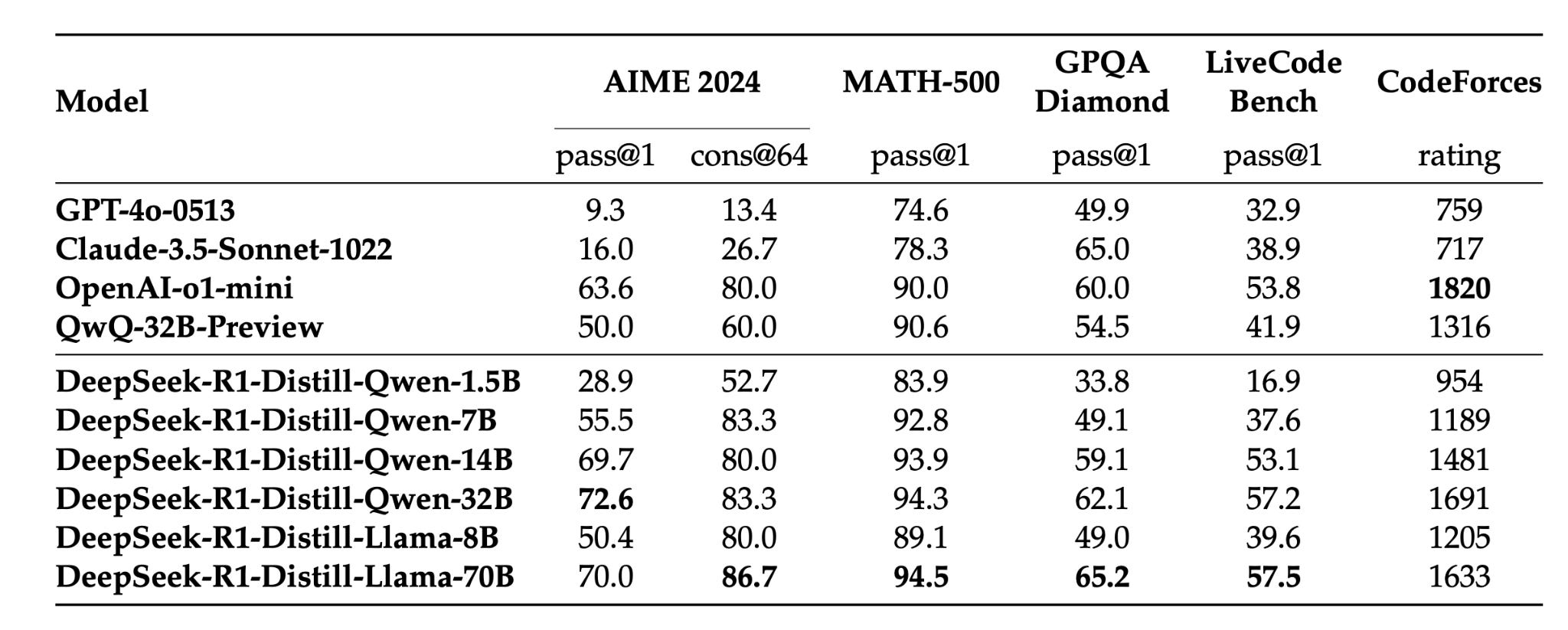
Distilled Models Perform Well
The distilled models also performed very well compared to existing similar models on multiple tasks.
Summary
The DeepSeek team has innovated on multiple facets of model building to create a best of the breed reasoning model. By open sourcing everything, they are also enabling innovation in the industry. It will be very fascinating to see how these innovations power more improvements in LLMs.











