What is a Foundation Model?

I recently moderated a panel on Foundation Models at the Founder’s Creative engineering summit. We started with a simple warm-up question for our audience: “What is a Foundation Model?” Surprisingly, only about 15% of the 100+ engineers in the room could answer. Even within that small group, the definitions varied widely. This experience, along with a similar one at a UC Berkeley paper reading session, highlighted a fundamental gap in understanding. What actually is a foundation model?
I recommend that you pause here and and think about how you define it before proceeding. Don’t forget to add it to the comments section below.
The term Foundation Model was introduced and defined in the 2021 report titled Foundation Models: Opportunities and Risks of Large AI Models from Center for Research on Foundation Models (CRFM) and Institute for Human-Centered Artificial Intelligence (HAI) at Stanford University. I have pulled out three relevant nuggets from the report:
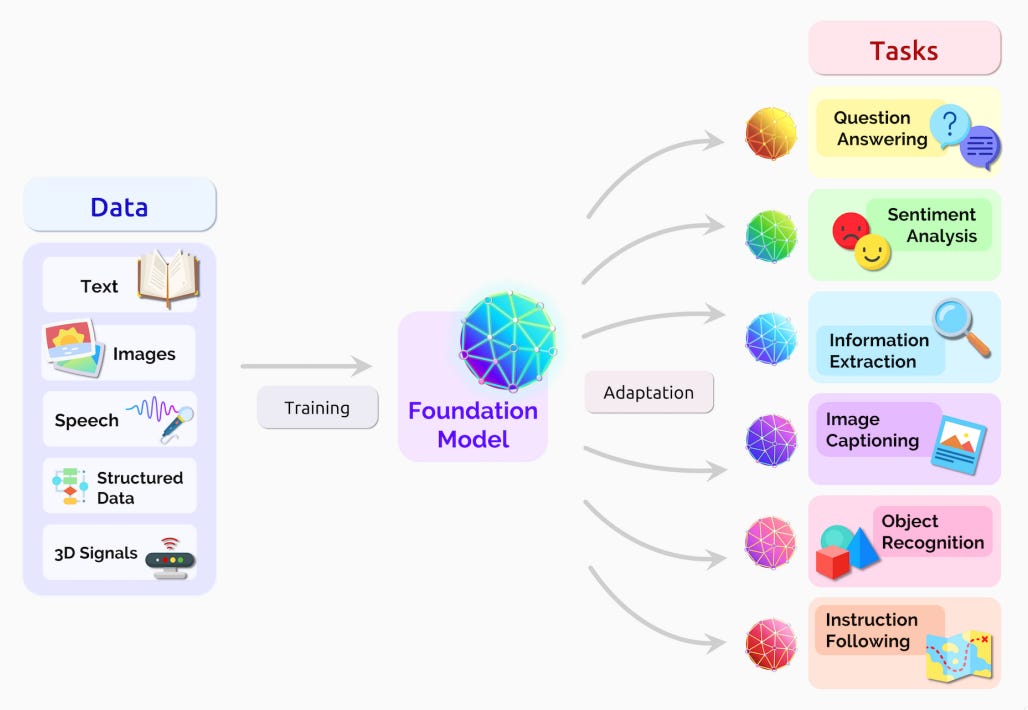
A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks
On a technical level, foundation models are enabled by transfer learning and scale.
Foundation model designates a model class that are distinctive in their sociological impact and how they have conferred a broad shift in AI research and deployment.
Combined together, we have a very clear definition of foundation model, in terms of how it is created, its capabilities and impact:
-
Massive Scale: Built with large number of parameters to capture intricate data relationships and trained on a very large corpus of data.
-
Self supervised learning: Trained using self supervised learning and hence does not need human annotations at scale.
-
Versatile: Can be adapted to new tasks through fine-tuning, prompt-based learning, or few-shot/zero-shot methods without full re-training.
-
Impact: Causing a major and broad shift in multiple domains with real world impact on people from all walks of life.
The selection of the term “Foundation” was deliberate as well:
The word “foundation” specifies the role these models play: a foundation model is itself incomplete but serves as the common basis from which many task-specific models are built via adaptation. We also chose the term “foundation” to connote the significance of architectural stability, safety, and security: poorly-constructed foundations are a recipe for disaster and well-executed foundations are a reliable bedrock for future applications
Arguably, we can limit the definition to the capabilities and impact and say that
Foundation model is versatile, adaptable to new tasks without full retraining, and has a significant real-world impact on daily life.
That is it, very simple and yet has a lot behind it. What do you think? Do you agree with this definition? Have you seen usage of the term in any other context?
DeepSeek’s Model Training Methodology

In the previous post, we explored how the DeepSeek team utilized an HPC codesign approach. By enhancing both the model architecture and the training framework, they were able to train DeepSeek models effectively while using fewer resources. In this article, we will delve into the innovative techniques they employed in their training methodology.
Large Scale Reinforcement Learning
DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation. This computation ranges from generating hundreds to thousands of reasoning tokens, allowing the model to explore and refine its thought processes in greater depth
One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously.
– DeepSeek-R1 paper
One of the primary innovations from the DeepSeek team is the application of direct, large-scale unsupervised Reinforcement Learning (RL) for LLM training. Their research demonstrates that the use of RL naturally enhanced the model’s reasoning abilities.
Reinforcement learning (RL) has been used extensively in multiple domains, including robotics. It is a machine learning technique where the model learns to make decisions based on feedback. Desired behaviors are rewarded, and undesired behaviors are punished.
At a high level, the RL learning process involves an agent (the model being trained) and an interpreter model. The interpreter model reviews the agent’s results and takes input from the environment to determine a reward to apply to the model.

RL enables an agent to learn optimal strategies in complex environments by interacting directly with the environment and focusing on maximizing long-term rewards. This makes the model particularly adept at handling dynamic, uncertain situations where immediate feedback may not be available. In contrast, traditional machine learning methods often rely on pre-labeled datasets. RL essentially helps the model learn by experiencing the consequences of its actions and adapting its behavior to achieve the best possible outcome.
Existing Proximal Policy Optimization (PPO)
While there are many reinforcement learning algorithms, PPO, introduced by OpenAI in 2017, has been the default RL algorithm since 2018.
PPO’s inner workings
As shown in Fig 2 below, PPO uses four models:
-
Policy Model: This is the LLM model being tuned.
-
Reference Model: This is identical to the policy model, but it’s frozen and used to reduce model divergence.
-
Reward Model: This is a pre-trained model that evaluates the reward for generated text.
-
Value Model: This is trained as part of the RL process to estimate the long-term value for the generated output.
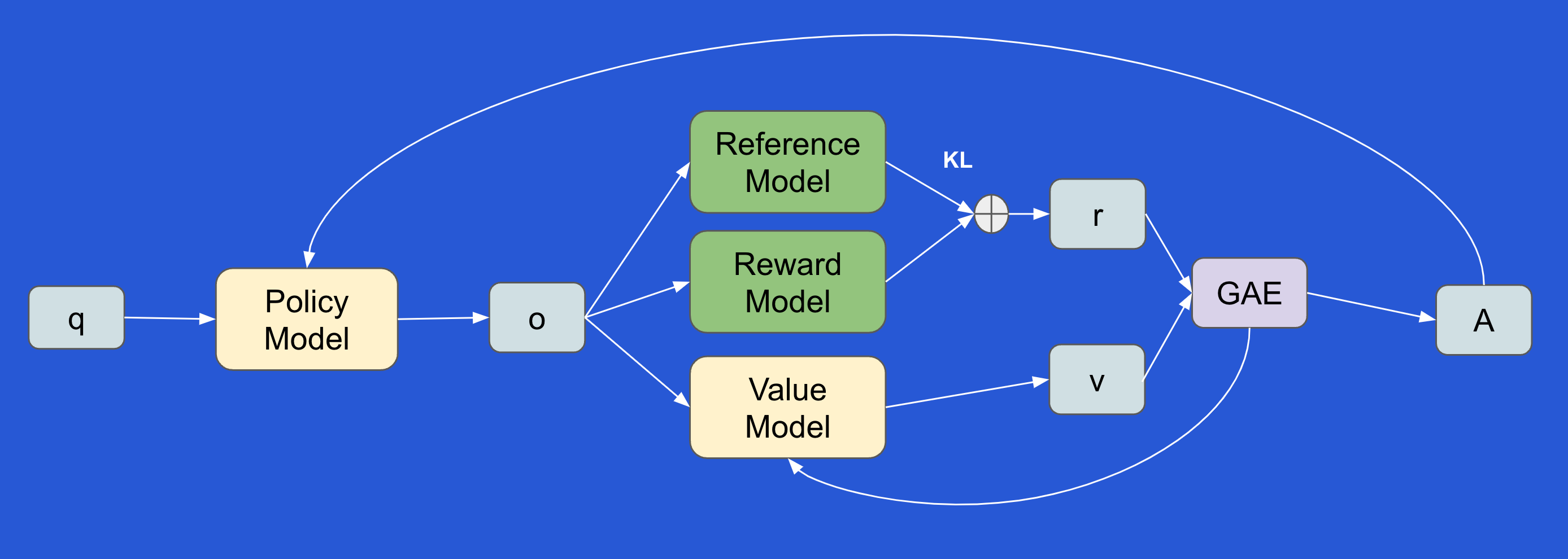
The PPO Process
-
A query (q) is submitted to the policy model, which generates an output (o).
-
The reward model computes a reward (r) for the output.
-
The value model estimates a value (v) for the output.
-
The Generalized Advantage Estimation (GAE) function combines r, v, and the reference model output to estimate the advantage (A).
-
The advantage is then used to update the policy model weights.
Key Takeaway
PPO’s use of four models makes it compute-intensive, presenting challenges for large-scale RL implementations.
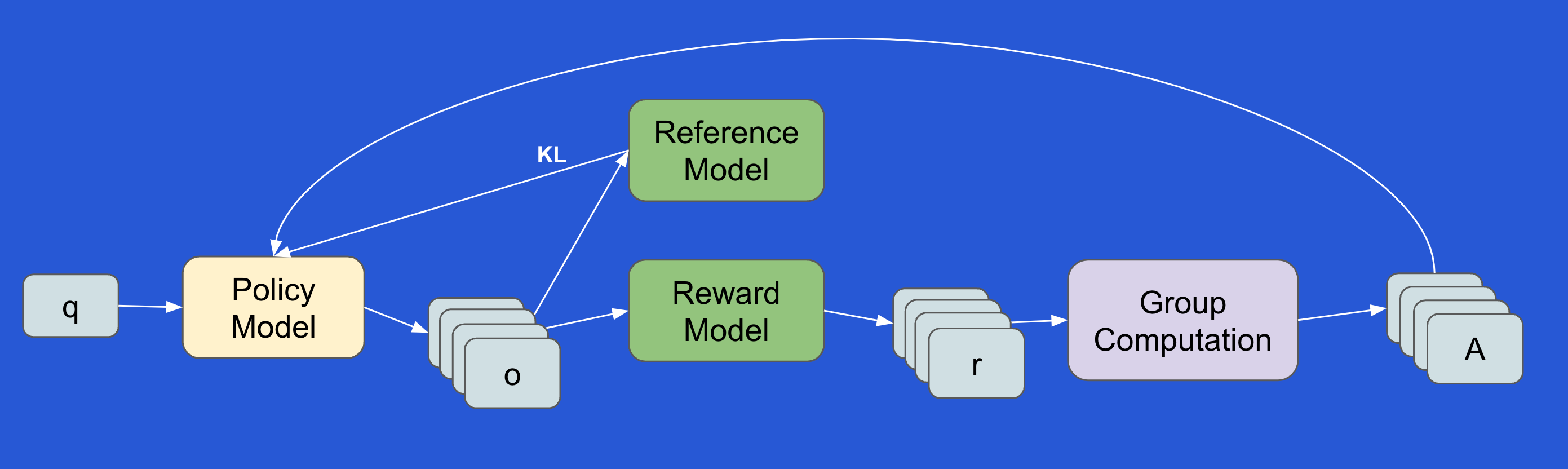
DeepSeek’s Group Relative Policy Optimization (GRPO)
The DeepSeek was able to address the scaling challenges by simplifying two key parts of PPO:
-
replacing a learnt value model with a simpler rules based reward computation
-
simplified KL regularization
With these optimizations, the team was able to use RL at scale during pre-training of the model.
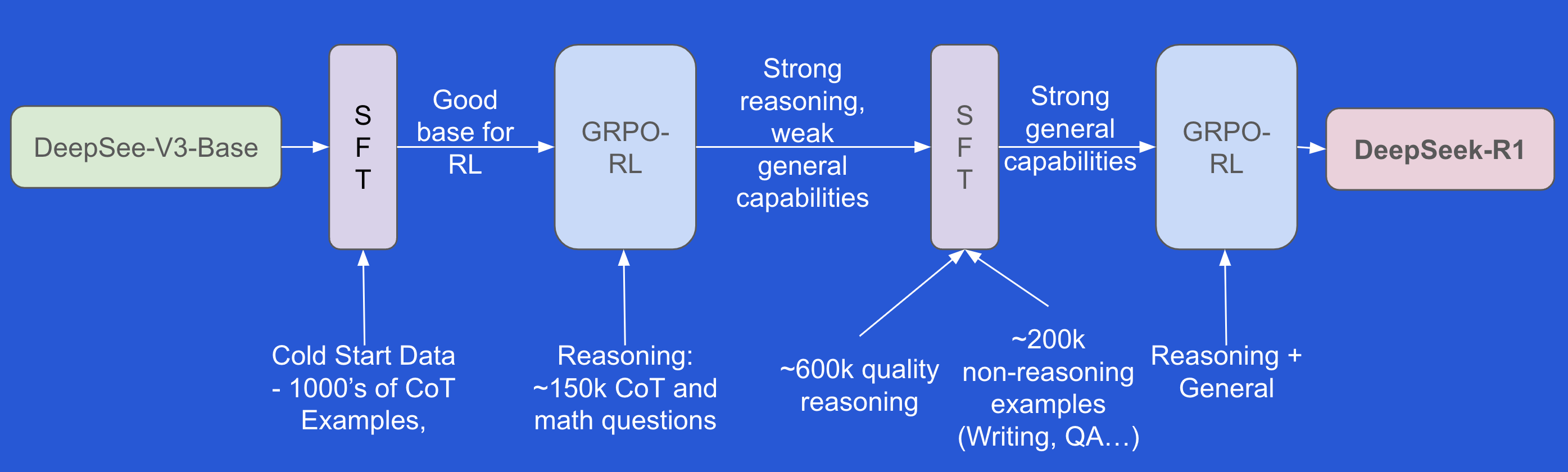
Four Stage Training Pipeline
The use of large-scale unsupervised RL led to the development of a strong reasoning model. However, this model encountered challenges related to readability, language mixing, and generalization to non-reasoning tasks. To address these issues, the team devised a new four-stage training pipeline that incorporates two supervised fine-tuning (SFT) and two reinforcement learning (RL) stages.
The initial SFT stage utilizes high-quality cold start data to stabilize the subsequent RL step, which in turn enhances the model’s reasoning capabilities. This is followed by another SFT stage that employs rejection sampling to further strengthen the model and includes non-reasoning examples to improve its performance on non-reasoning tasks.
The final RL stage incorporates more general tasks to align the model with human expectations and includes a reward for readability and single language usage in its policy optimization step.
DeepSeek-R1 Results
The DeepSeek-R1 model showcased impressive results, with the team summarizing their findings as follows:
-
DeepSeek-R1’s performance was on par with OpenAI-o1-1217 on multiple tasks.
-
The model’s strong document analysis capabilities were evident in its performance on FRAMES, a long-context-dependent QA task.
-
DeepSeek-R1 displayed strong instruction-following capabilities, based on impressive results on the IF-Eval benchmark.
-
The model’s strengths in writing tasks and open-domain question answering were highlighted by good performance with AlpacaEval2.0 and ArenaHard.
-
DeepSeek-R1’s performance on the Chinese SimpleQA benchmark was worse than DeepSeek-V3 due to the addition of Safety RL to control output (censorship?).
-
Large-scale reinforcement learning was highly effective for STEM-related questions with clear and specific answers.
-
Reasoning models were generally better at handling fact-based queries.
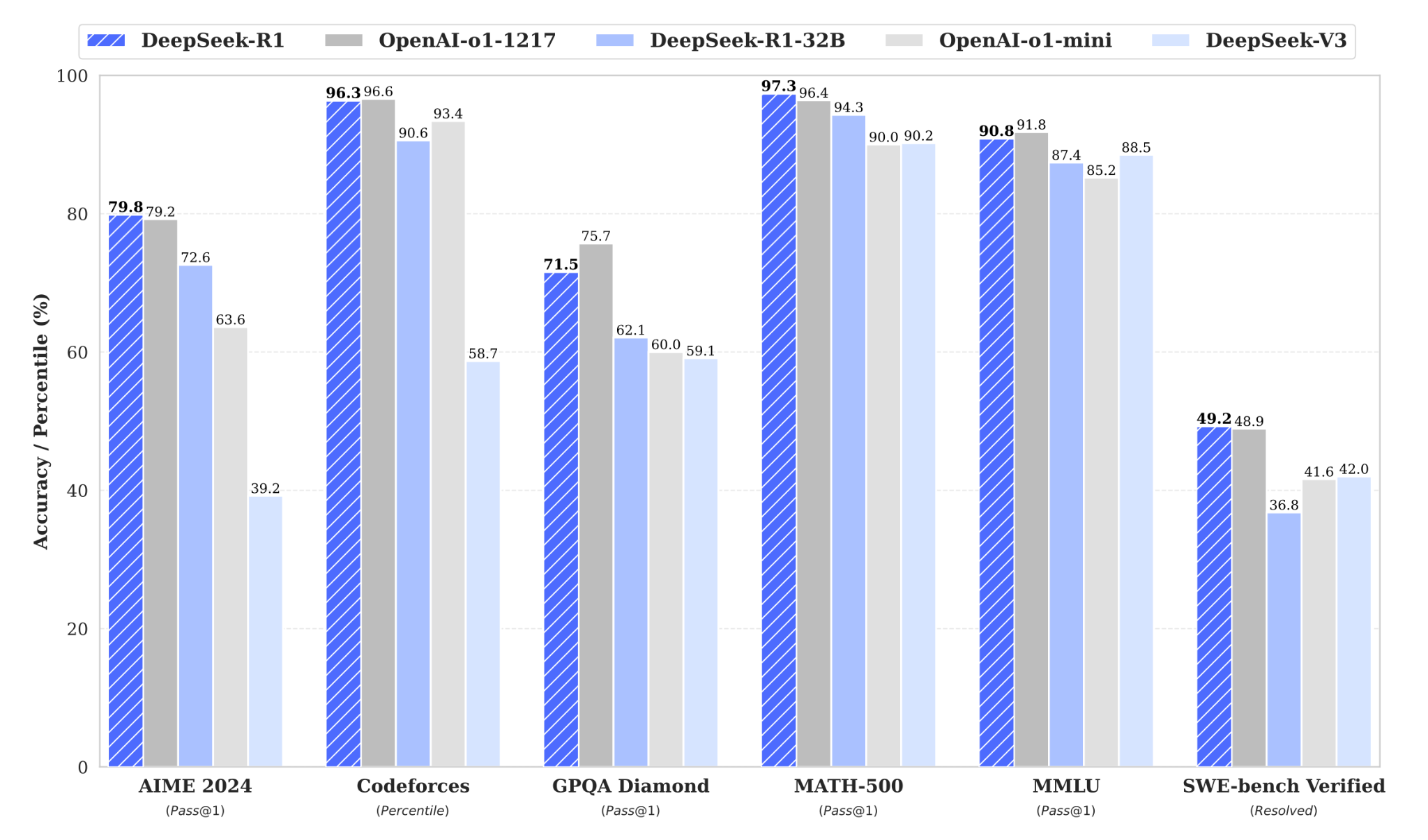
-
Reasoning tasks
-
79.8% Pass@1 on AIME 2024
-
97.3% on MATH-500
-
2,029 Elo rating on Codeforces
-
-
Knowledge
-
90.8% on MMLU
-
84.0% on MMLU-Pro
-
71.5% on GPQA Diamond
-
-
Others
-
87.6% on AlpacaEval 2.0
-
92.3% on ArenaHard
-
Model Distillation
Distillation Creates Smaller, More Efficient Models
The DeepSeek team found that smaller, denser models trained on data from the larger R1 model, through a process called distillation, performed very well on benchmarks. This finding can help create smaller, more efficient models in the industry.
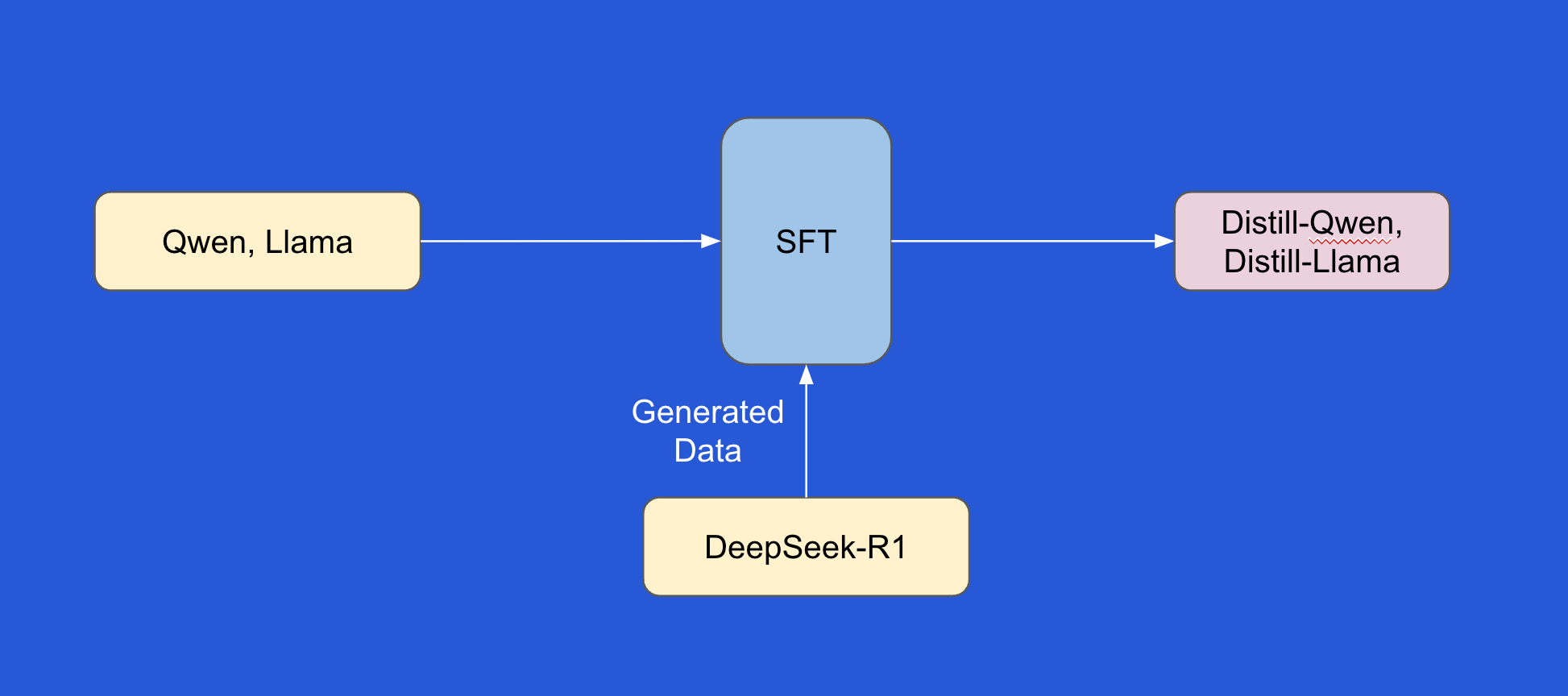
Six Distilled Models Created
Using the Llama and Qwen models, the team created six distilled models:
-
Distill-Qwen-1.5B (1.5 billion parameters)
-
Distill-Qwen-7B (7 billion parameters)
-
Distill-Qwen-14B (14 billion parameters)
-
Distill-Qwen-32B (32 billion parameters)
-
Distill-Llama-8B (8 billion parameters)
-
Distill-Llama-70B (70 billion parameters)
Distilled Models Perform Well
The distilled models also performed very well compared to existing similar models on multiple tasks.
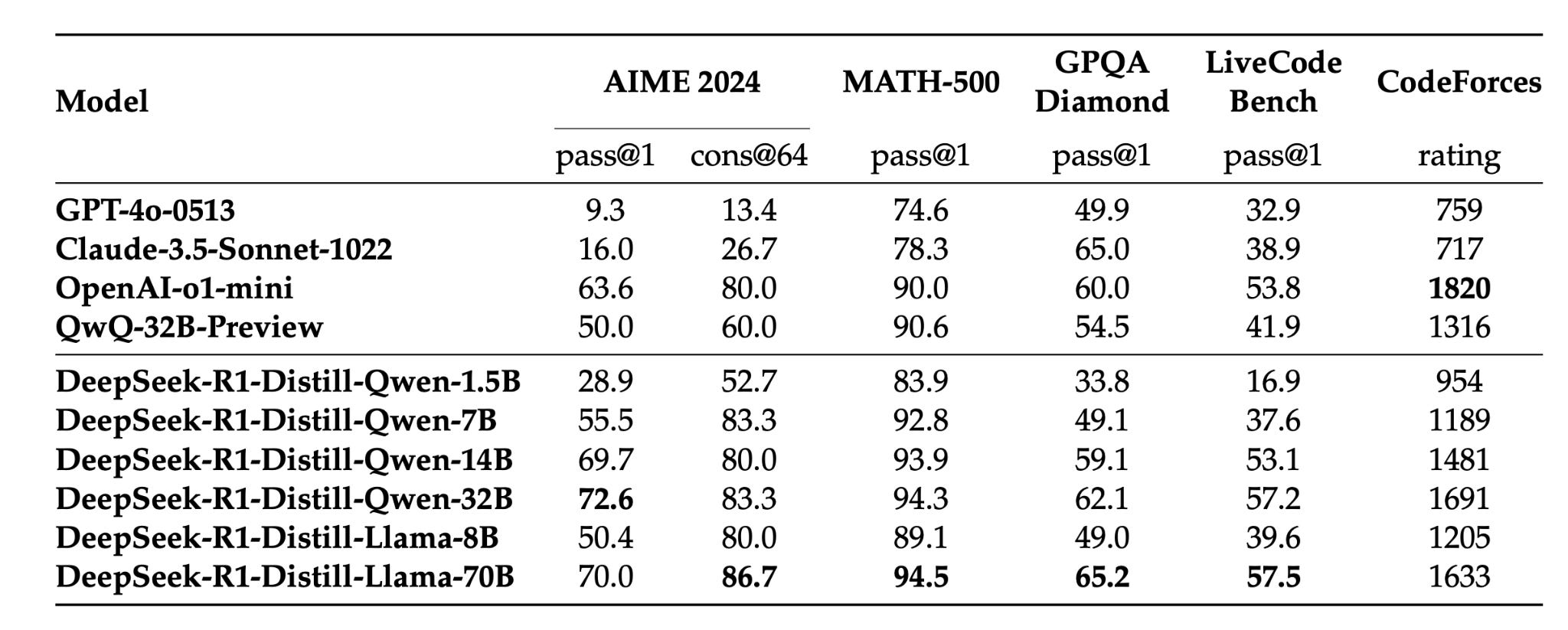
Summary
The DeepSeek team has innovated on multiple facets of model building to create a best of the breed reasoning model. By open sourcing everything, they are also enabling innovation in the industry. It will be very fascinating to see how these innovations power more improvements in LLMs.
Model Architecture Behind DeepSeek R1

In our earlier introductory post, we discussed the critical innovations and emphasis on scaling that have propelled advancements in recent years, as shown by the development of OpenAI models.
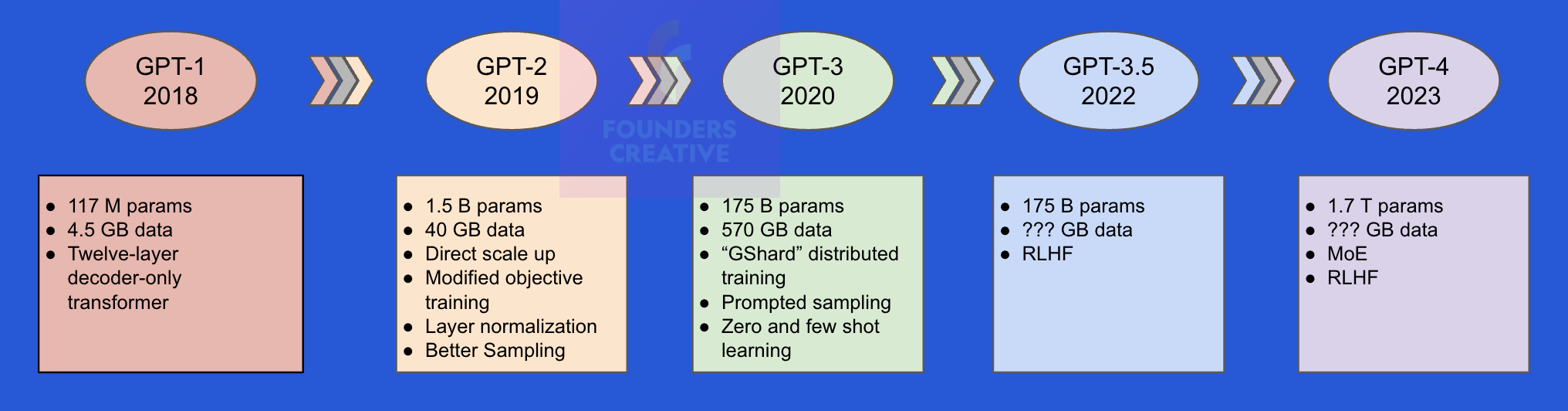
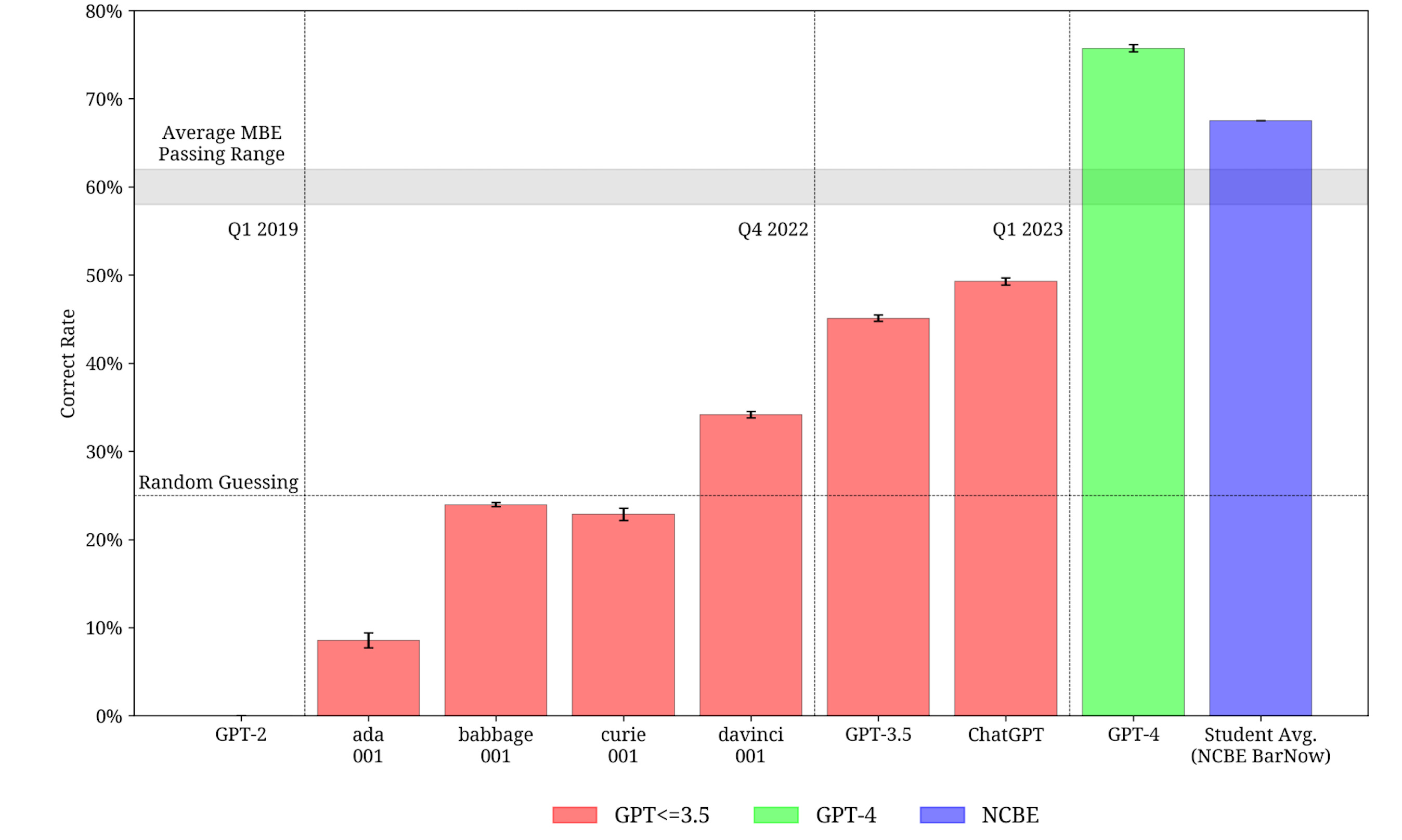
As predicted by the scaling laws, the performance of these models have shown steady growth. Now, GPT-4 outperforms the average student on the Multistate Bar Exam (MBE), which is a rigorous series of tests required for practicing law in the United States.
Other model families like Google’s Gemini, Facebook’s Llama, Mistral AI’s Mistral too follow a very similar trend. However, the DeepSeek team was compelled to shift their focus due to US trade restrictions. Instead of scaling, they concentrated on model architecture, training methodologies, and the training framework. Over 18 months, they developed numerous tweaks in each area, which they published in a series of four papers.
Let us now dive into the actual improvements, starting with model architecture.
DeepSeek-MoE
MoE Architecture And Challenges
The Mixture of Experts (MoE) model architecture, which has been around for a while and used by other teams as well, breaks down the single large feedforward network in the transformer block into multiple feedforward networks called experts. For any given token, only a subset of these experts are activated by a router component, reducing the number of FLOPs done per token. This architecture includes a router component that decides which experts to activate for a given token.
However, this approach presents scaling and performance challenges:
-
Network Collapse: The router may learn to activate only a smaller subset of experts for all tokens, creating an imbalance. This is typically addressed using Auxiliary-Loss based load balancing, which adds a penalty for over or under utilization of an expert to the loss function. However, being part of the loss function, this impacts the actual weights learned by the model, decreasing its performance.
-
Communication Overload: In distributed training, where experts are distributed across devices, the constant exchange of tokens and weights between devices leads to significant communication overhead.
-
Generalization Issues: The specialized nature of MoE experts can hinder the model’s ability to generalize across different tasks.
DeepSeekMoE Innovations
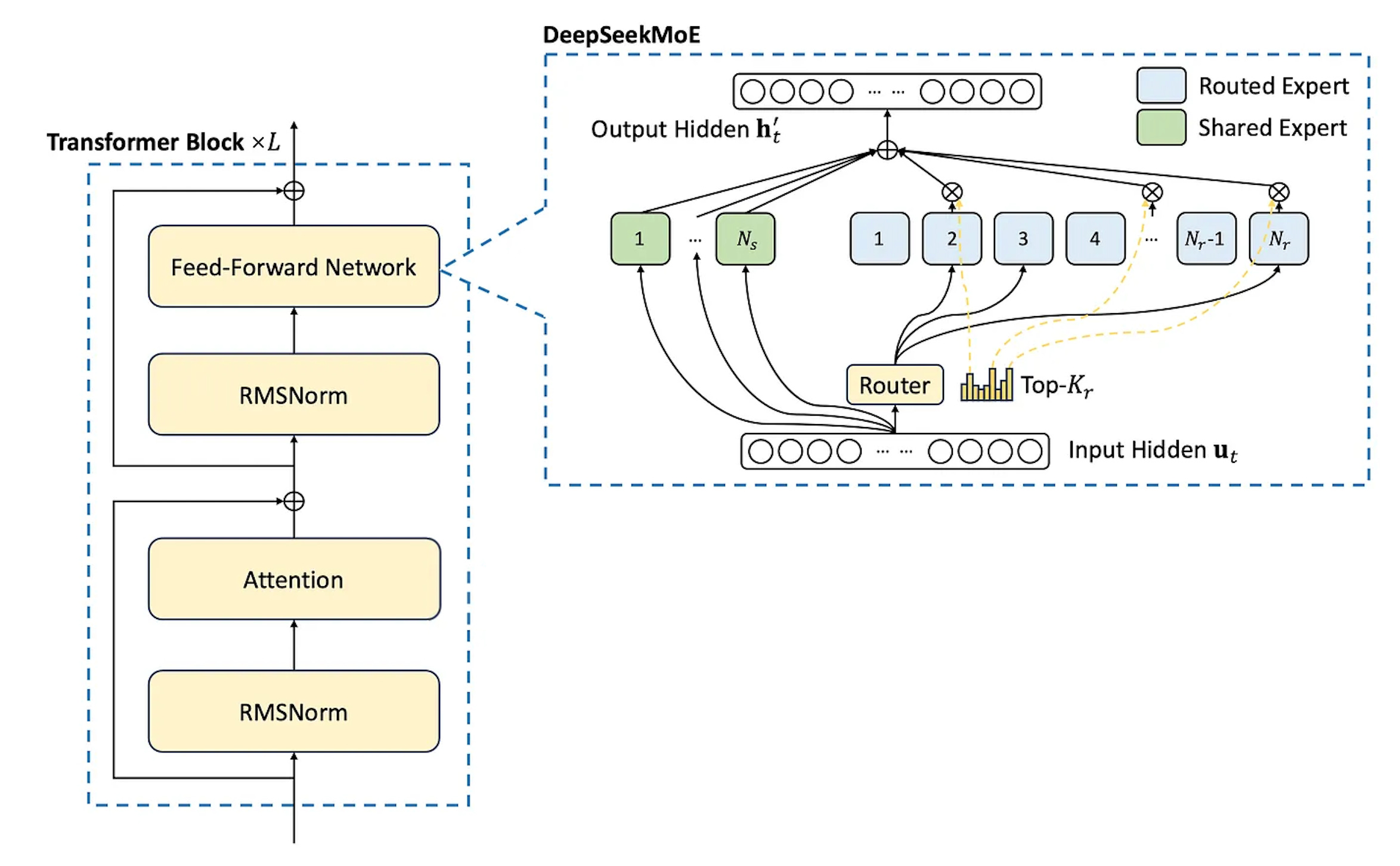
The DeepSeekMoE architecture, shown above, incorporates several enhancements to address the challenges posed by training MoE models.
-
Auxiliary-Loss-Free Load Balancing: To counter the issue of model collapse, a novel dynamic bias term was introduced. This term is exclusively used for updating the token affinity score for routing and is disregarded during model weight updates. This strategy effectively prevents model collapse without compromising performance.
-
Shared Experts: The architecture also includes shared experts that learn from all tokens. This reduces redundancy among specialized experts, promoting efficiency and enhancing the model’s generalization capabilities across diverse tasks.
-
Framework improvements: Additionally, substantial improvements were made to the model training framework to mitigate communication overhead and reduce compute cost. These include:
-
FP8 Mixed Precision: Matrix multiplications utilize the FP8 data format, halving memory usage and data transfer. Block-wise scaling and periodic “promotion” to FP32 after brief accumulation intervals prevent numeric overflow/underflow errors, maintaining numerical stability despite the reduced numeric range of FP8.
-
DualPipe Parallelism: This technique overlaps forward and backward computation with the MoE all-to-all dispatch, optimizing network communication, especially across InfiniBand.
-
PTX-Level & Warp Specialization: Warp-level instructions in PTX were fine-tuned, and the chunk size for all-to-all dispatch was auto-tuned to fully leverage InfiniBand and NVLink. Additionally, microcontroller allocation for communication versus compute tasks was adjusted. These optimizations ensure that communication does not impede computation.
-
Multi-Head Latent Attention (MLA)
The transformer architecture’s multi-head attention involves Query, Key, and Value vectors, which can be as large as the embedding dimensions divided by the number of attention heads. The MLA approach reduces the FLOPs per token by using down projection matrices to fold these vectors into smaller “latent” vectors, some of which are also cached. This approach helps reduce the FLOPs done per token.
In order to avoid any performance drop, the team also implemented:
-
Dynamic Low-Rank Projection: MLA adjusts the compression strength for Key/Value vectors based on sequence length.
-
Adaptive Query Compression: Adaptive scaling of the query at different layer depths. Early layers maintain expressiveness with higher-dimensional queries, while deeper layers compress more aggressively.
-
Joint KV Storage: Shared KV storage further reduces memory traffic during multi-node inference.
-
Layer-Wise Adaptive Cache: Instead of caching all past tokens for all layers, V3 prunes older KV entries at deeper layers to manage memory usage with 128K context windows.
The architecture diagram for MLA, showing the compression of queries, keys, and values using down projection matrices, is displayed below.

Multi-Token Prediction
The architecture was enhanced with MTP modules by the DeepSeek team to enable the model to predict multiple future tokens simultaneously. This allows for a deeper understanding of context and generation of more coherent sequences due to the model’s ability to look ahead further into the sequence. Compared to traditional single-token prediction methods, this significantly improves both efficiency and performance. The diagram below illustrates the MTP module alongside the main module.
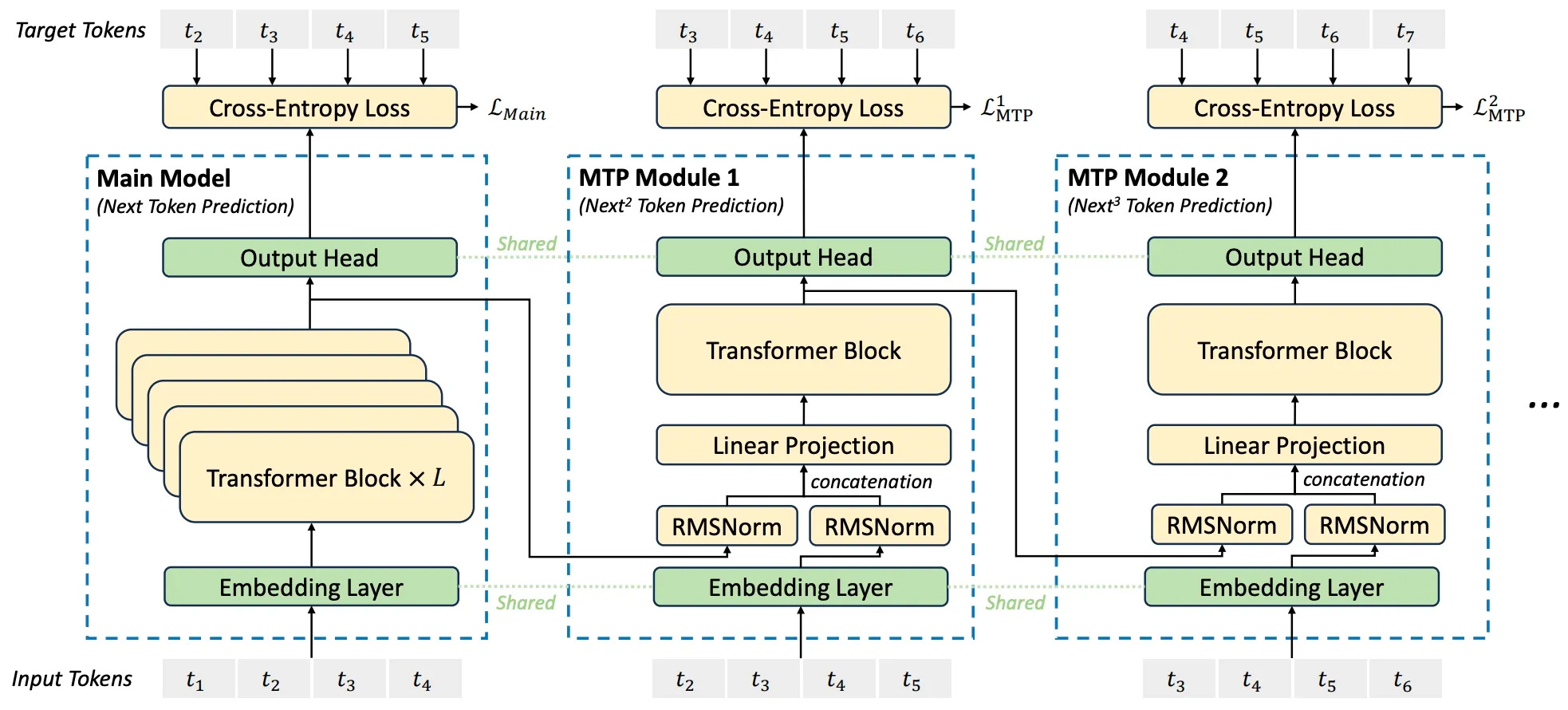
Conclusion
This concludes this section. We explored three primary architectural patterns that the DeepSeek team adapted and enhanced to develop the DeepSeek-R1 model: DeepSeekMoE, Multi-Head Latent Attention, and Mult-Token Prediction. We also reviewed various improvements made to the training framework to accommodate the architectural changes. In the next and final post of this series, we will examine the changes made to the model training methodology.
Finally I have a shameless plug – I will be leading a panel discussion on foundation models and, ofcourse, DeepSeek-R1 at the engineering summit on March 28 at Palo Alto, California. A bunch of very enthusiastic volunteers of Founder’s Creative are organizing the event. We have a very interesting lineup of speakers and panels. If you are in the San Francisco Bay area around that time then you should take a look.

What Is Behind The DeepSeek Hype?

DeepSeek R1, a new open-sourced large language model released by a Chinese startup in January 2025, has garnered significant attention. Developed on a tight budget and timeline, it rivals the industry’s top LLMs. While concerns persist around security, safety, veracity, and accuracy, the technical innovations behind the model are undeniable. This tri-part series will focus exclusively on exploring these technical advancements.
First Some Context
To gain a better understanding of DeepSeek’s innovations and contributions, it is crucial to first examine the broader context surrounding the rapid rise of Large Language Models (LLMs) and the current industry practices and trends. The way for the GenAI revolution has been paved by a long list of innovations in deep learning and NLP research over the past few decades. However, for sake of time, we will keep our highly opinionated review short and just focus on the recent few innovations since transformer model architecture.
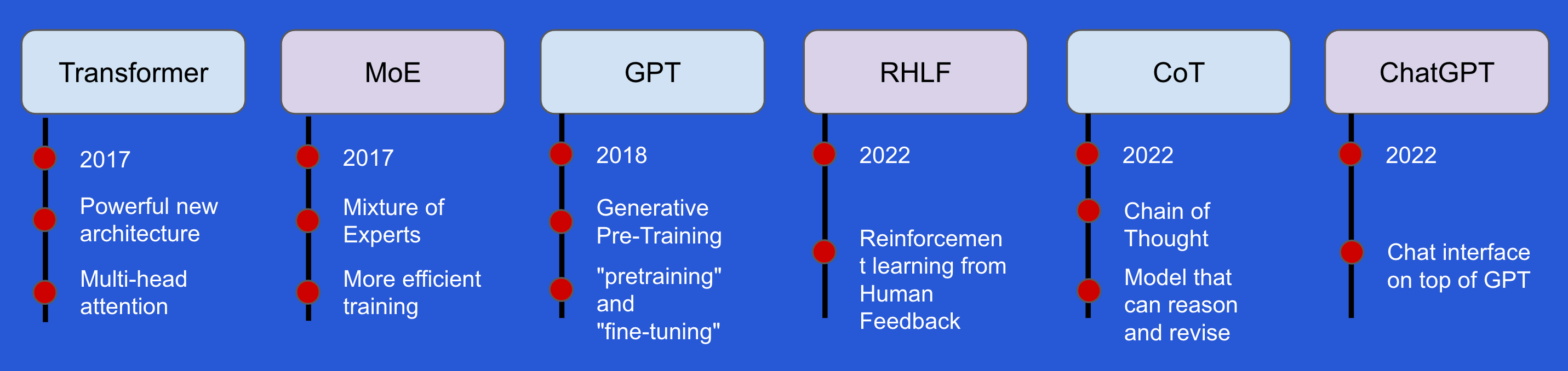
Transformer Architecture
The 2017 paper “Attention Is All You Need” introduced the Attention mechanism, which allows the model to focus on different parts of a sequence to effectively complete the task. For example, if the model is given the sentence “he walked to her home” and asked to classify the gender of the main character, the Attention mechanism would give more weight to the word “he“. The below diagram shows the encoder part of the encoder-decoder transformer architecture in that paper.
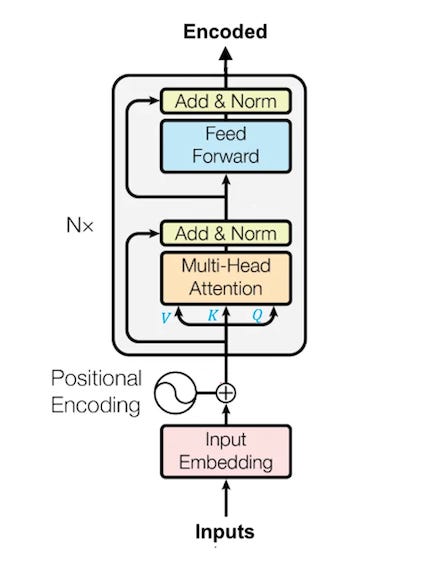
Mixture of Experts (MoE) Architecture
Mixture of Experts (MoE) architecture then emerged, which created a sparser network with specialized segments called experts. Rather than updating the parameters of one large feedforward network, a subset of many smaller feedforward networks is updated. This decreased the computational requirements during both training and inference, allowing for the training of larger networks with more data. Below figure shows how the feed forward network in the transformer’s encoder (highlighted in blue) was broken down into multiple smaller FFNs in MoE.
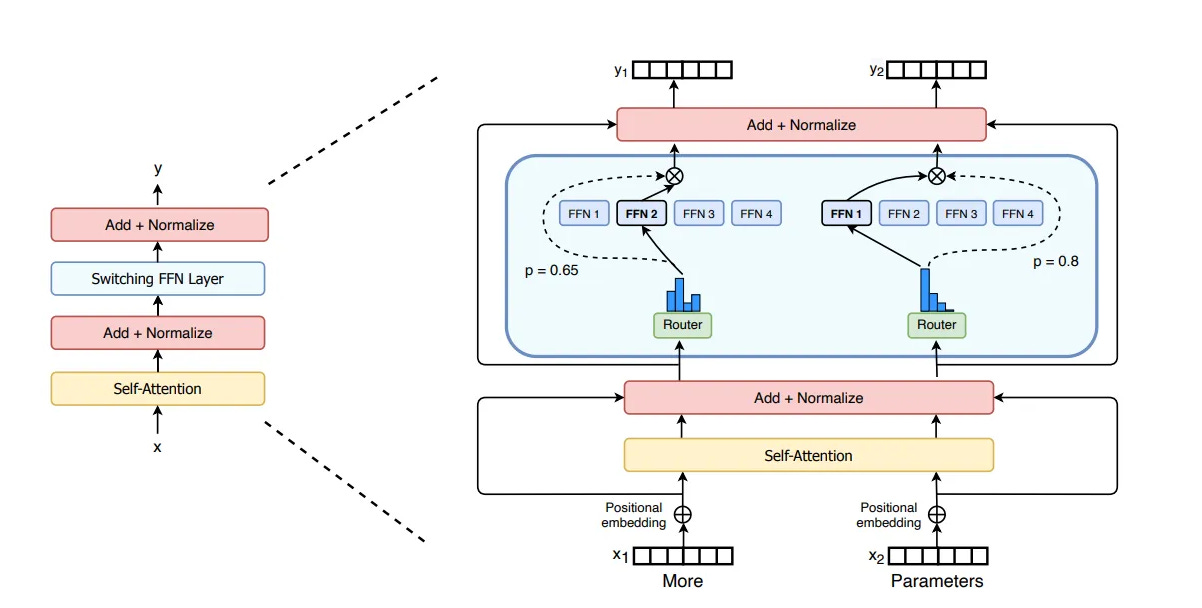
Two Stage Training Pipeline – GPT, SFT and RLHF
The next big step was in the training methodology used to train LLMs. The 2018 GPT paper introduced a two-stage training pipeline, consisting of unsupervised Generative Pre-Training (GPT) on massive datasets followed by Supervised Fine Tuning (SFT). In some sense, the true birth of generative AI revolution was marked by this paper. The InstructGPT paper from 2022 then added a third step: Reinforcement Learning From Human Feedback (RLHF). This step uses human annotators to score the model’s output and then fine-tunes the model further, ensuring alignment with human expectations.
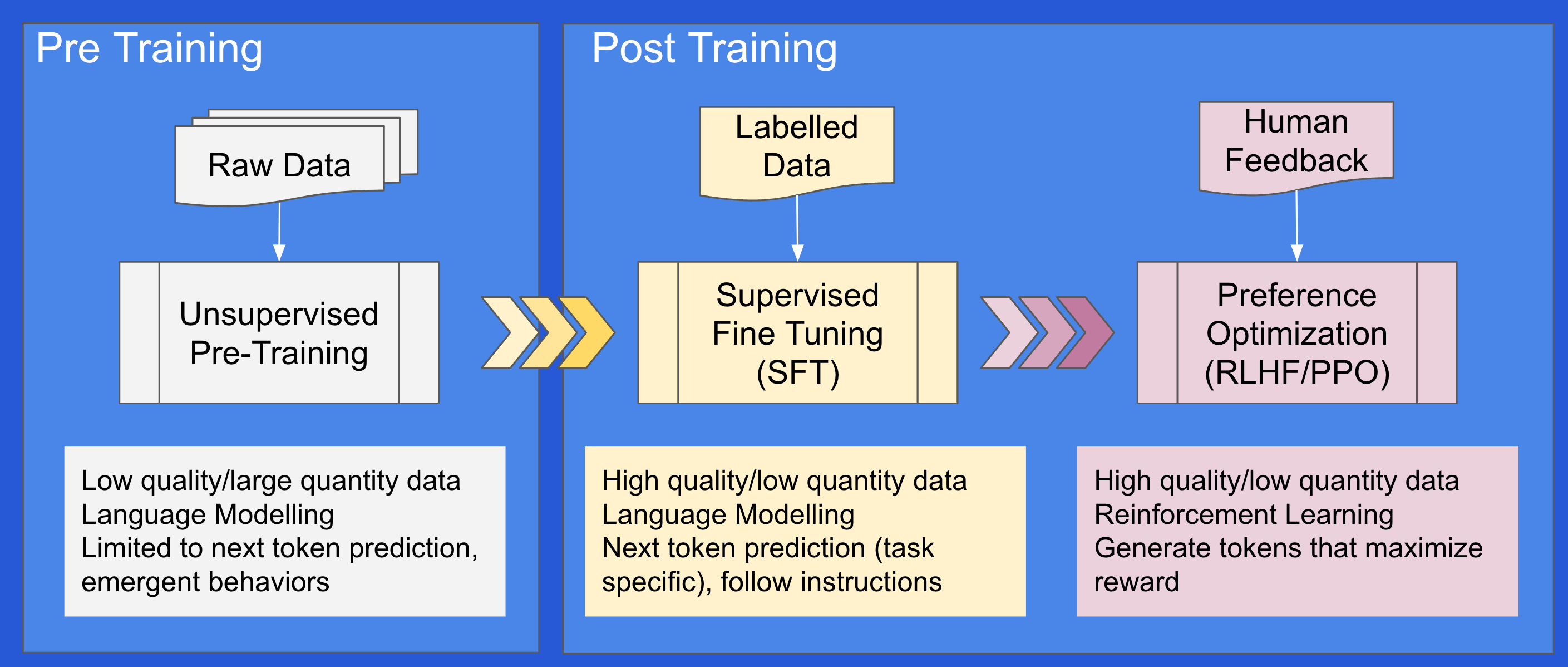
Chain of Thought
The focus then shifted to post-training or test-time improvements with prompt engineering, specifically Chain of Thought reasoning. Chain of thought prompting decomposes complex tasks into a series of logical sub-tasks, guiding the model to reason in a human-like manner. Finally, ChatGPT was introduced as a user-friendly chat interface.
Scaling Laws
The last stop on our tour is scaling laws. This theoretical innovation provided the framework that shifted industry focus from pre-training to post-training and finally to test-time.
The 2020 publication Scaling Laws for Neural Language Models introduced the concept that LLM performance improves with increases in model size, dataset size, and compute used for training. This spurred a focus on scaling:
-
Initially, pre-training scaling was the focus, with efforts to increase the size of models, pre-training datasets, and compute clusters.
-
When the limits of internet data were reached, the focus shifted to post-training scaling, using Reinforcement Learning with Human Feedback (RLHF) and Supervised Fine Tuning (SFT). High-quality, human-annotated, task-specific data for fine tuning became a key differentiator for many companies.
-
As post-training gains diminished, test-time scaling came into focus, using prompt engineering and Chain of Thought reasoning.
Enter DeepSeek
The previous section highlighted that the industry was more focused on scaling these past few years, rather than model architecture or training methodologies. This is changing with DeepSeek’s announcement of its R1 model on January 20, 2025. US export restrictions on China seemingly limited scaling as an option to improve LLMs, forcing innovation across multiple aspects of model building, which can be categorized into three areas.
Model Architecture
-
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
-
Only 37 billion parameters activated out of 671 billion for each token
-
-
MLA – Multi-Headed Latent Attention
-
Compressing key/value vectors using down-projection and up-projection matrices for more optimal memory and compute use
-
-
Multi-Token Prediction Training Objective
-
Predicting more than 1 token at a time, again optimizing compute
-
Powers speculative decoding during inference to speed up inference
-
Training Methodology
-
Direct Reinforcement Learning on the Base Model
-
No supervised fine tuning (SFT)
-
Surfaced emergent CoT behaviors – self-verification, reflection etc.
-
-
New Group Relative Policy Optimization (GRPO)
-
Estimates from group score instead of using critic model
-
Rules based reward with accuracy and format rewards
-
-
New Four Stage Training Pipeline for Final Model
-
Cold start data
-
Reasoning oriented RL
-
Rejection sampling and SFT
-
RL for all scenarios for alignment
-
-
Distillation of Reasoning Patterns
-
Data generated by DeepSeek-R1 used to fine-tune smaller dense models like Qwen and Llama
-
Training Framework
-
FP8 Mixed Precision Training Framework
-
Previous approaches of Quantization were about converting the weights form FP32 to FP8 after model training
-
-
DualPipe Algorithm Pipeline Parallelism
-
Bidirectional pipeline scheduling and overlapping communication with computation
-
Reduces pipeline bubbles and communication overhead introduced by cross-node expert parallelism
-
Near-zero communication overhead while scaling the model and employing fine-grained experts across nodes
-
-
Better Utilization of InfiniBand and NVLink Bandwidths
-
Improved cross-node communication
-
20 of the 132 processing units on each H800 specifically programmed to manage cross-chip communications
-
-
Memory Optimizations
-
Selective compression and caching
-
Conclusion
This concludes our first post this three part series on DeepSeek. We explored the past few years when scaling laws drove the industry to focus on scaling datasets, compute, and model size to enhance LLMs. We briefly discussed key innovations – Transformer architecture, Mixture of Experts architecture, 2-stage training pipeline, prompt engineering, and Chain of Thought – that facilitated this scaling. Additionally, we did a quick review of DeepSeek’s innovations, given their scaling limitations due to export restrictions. The technical details of these innovations will be explored in the upcoming posts. Stay tuned!