Model Architecture Behind DeepSeek R1

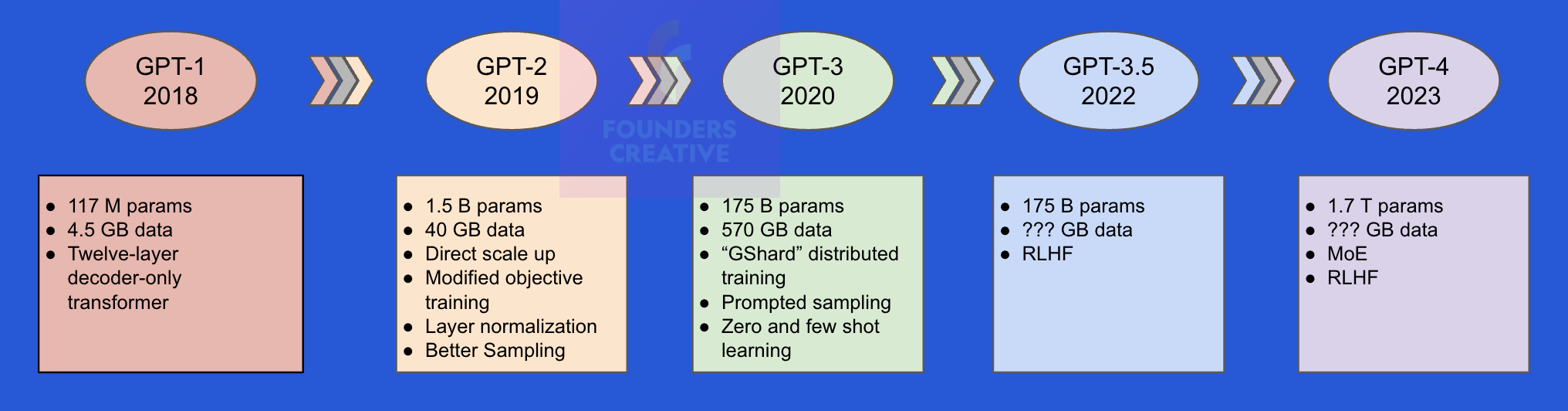
In our earlier introductory post, we discussed the critical innovations and emphasis on scaling that have propelled advancements in recent years, as shown by the development of OpenAI models.
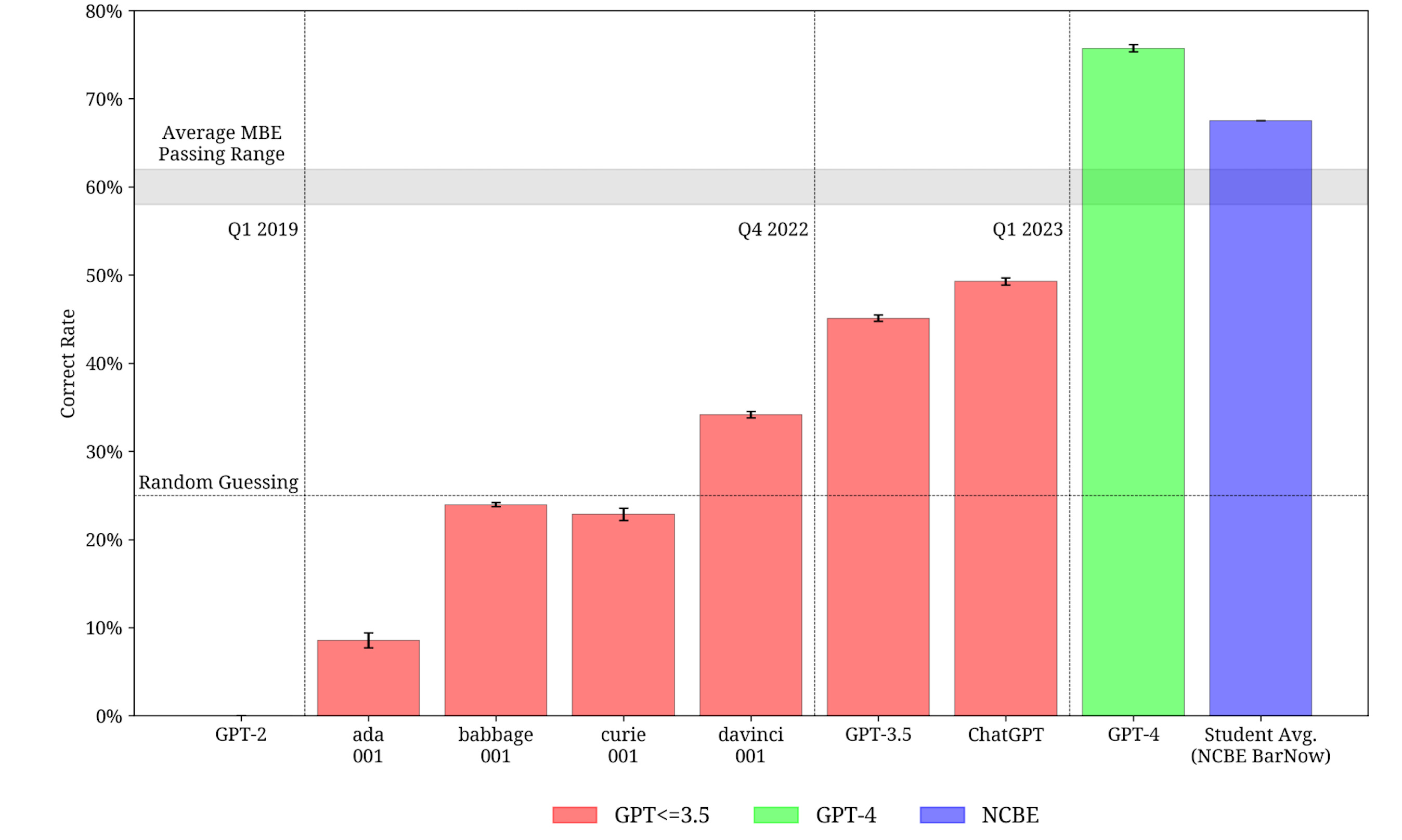
As predicted by the scaling laws, the performance of these models have shown steady growth. Now, GPT-4 outperforms the average student on the Multistate Bar Exam (MBE), which is a rigorous series of tests required for practicing law in the United States.
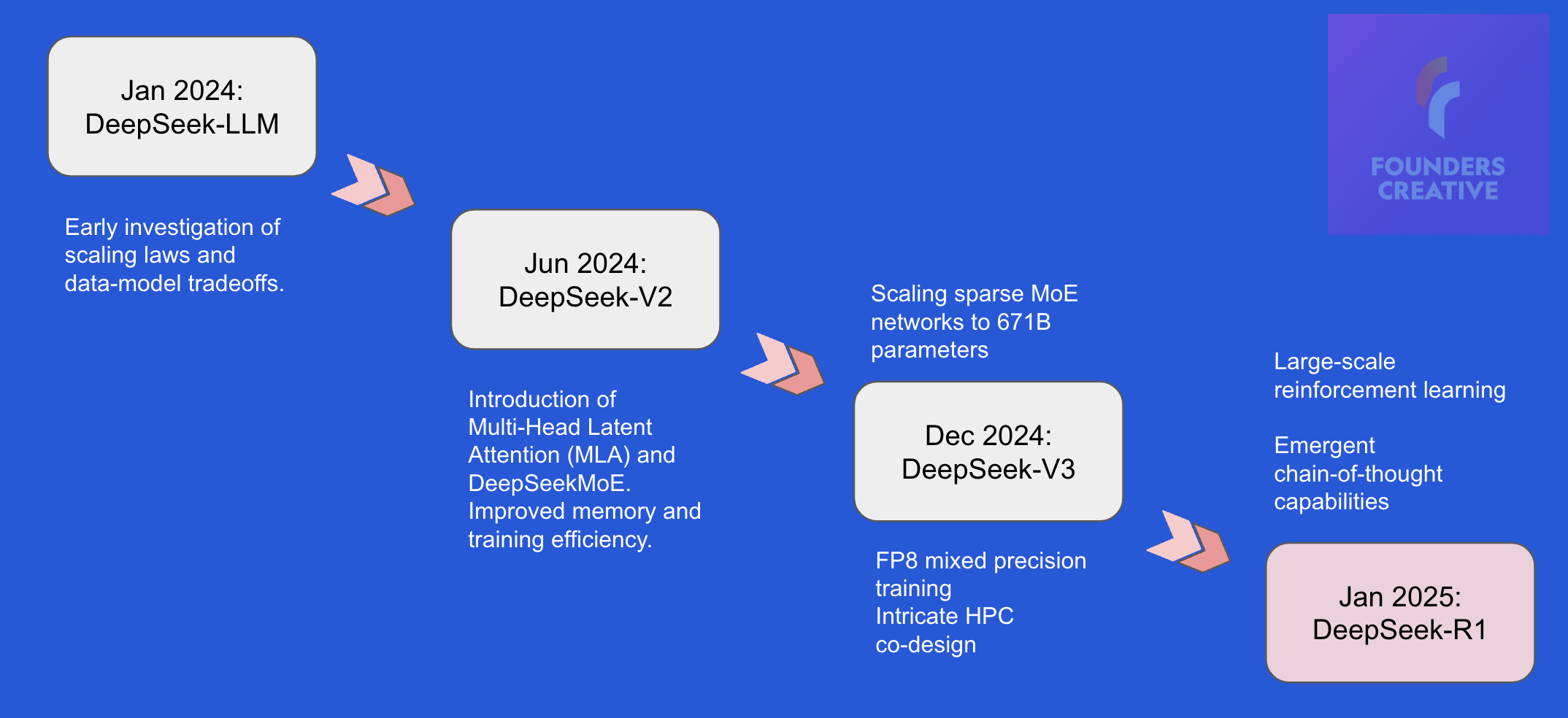
Other model families like Google’s Gemini, Facebook’s Llama, Mistral AI’s Mistral too follow a very similar trend. However, the DeepSeek team was compelled to shift their focus due to US trade restrictions. Instead of scaling, they concentrated on model architecture, training methodologies, and the training framework. Over 18 months, they developed numerous tweaks in each area, which they published in a series of four papers.
Let us now dive into the actual improvements, starting with model architecture.
DeepSeek-MoE
MoE Architecture And Challenges
The Mixture of Experts (MoE) model architecture, which has been around for a while and used by other teams as well, breaks down the single large feedforward network in the transformer block into multiple feedforward networks called experts. For any given token, only a subset of these experts are activated by a router component, reducing the number of FLOPs done per token. This architecture includes a router component that decides which experts to activate for a given token.
However, this approach presents scaling and performance challenges:
-
Network Collapse: The router may learn to activate only a smaller subset of experts for all tokens, creating an imbalance. This is typically addressed using Auxiliary-Loss based load balancing, which adds a penalty for over or under utilization of an expert to the loss function. However, being part of the loss function, this impacts the actual weights learned by the model, decreasing its performance.
-
Communication Overload: In distributed training, where experts are distributed across devices, the constant exchange of tokens and weights between devices leads to significant communication overhead.
-
Generalization Issues: The specialized nature of MoE experts can hinder the model’s ability to generalize across different tasks.
DeepSeekMoE Innovations
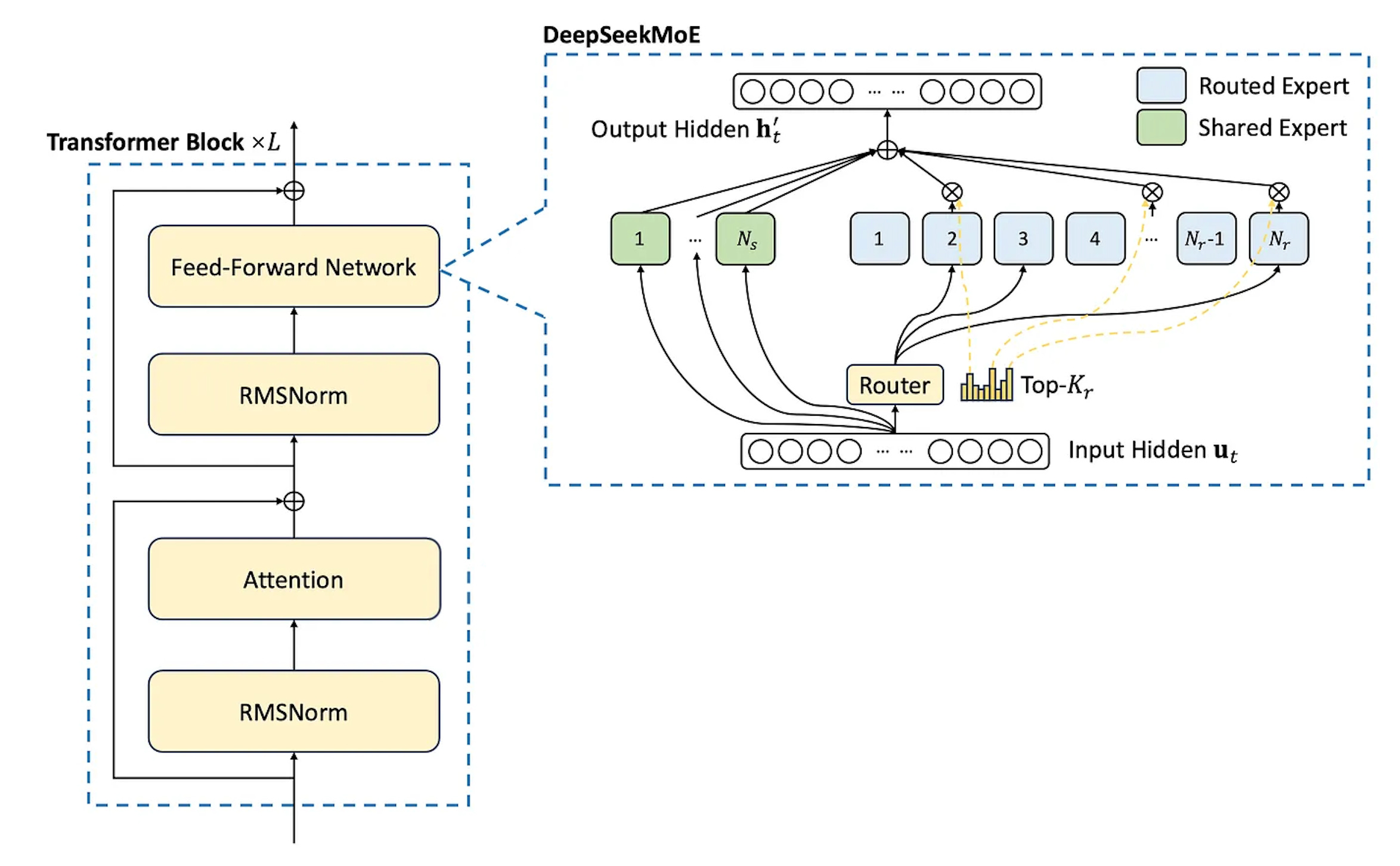
The DeepSeekMoE architecture, shown above, incorporates several enhancements to address the challenges posed by training MoE models.
-
Auxiliary-Loss-Free Load Balancing: To counter the issue of model collapse, a novel dynamic bias term was introduced. This term is exclusively used for updating the token affinity score for routing and is disregarded during model weight updates. This strategy effectively prevents model collapse without compromising performance.
-
Shared Experts: The architecture also includes shared experts that learn from all tokens. This reduces redundancy among specialized experts, promoting efficiency and enhancing the model’s generalization capabilities across diverse tasks.
-
Framework improvements: Additionally, substantial improvements were made to the model training framework to mitigate communication overhead and reduce compute cost. These include:
-
FP8 Mixed Precision: Matrix multiplications utilize the FP8 data format, halving memory usage and data transfer. Block-wise scaling and periodic “promotion” to FP32 after brief accumulation intervals prevent numeric overflow/underflow errors, maintaining numerical stability despite the reduced numeric range of FP8.
-
DualPipe Parallelism: This technique overlaps forward and backward computation with the MoE all-to-all dispatch, optimizing network communication, especially across InfiniBand.
-
PTX-Level & Warp Specialization: Warp-level instructions in PTX were fine-tuned, and the chunk size for all-to-all dispatch was auto-tuned to fully leverage InfiniBand and NVLink. Additionally, microcontroller allocation for communication versus compute tasks was adjusted. These optimizations ensure that communication does not impede computation.
-
Multi-Head Latent Attention (MLA)
The transformer architecture’s multi-head attention involves Query, Key, and Value vectors, which can be as large as the embedding dimensions divided by the number of attention heads. The MLA approach reduces the FLOPs per token by using down projection matrices to fold these vectors into smaller “latent” vectors, some of which are also cached. This approach helps reduce the FLOPs done per token.
In order to avoid any performance drop, the team also implemented:
-
Dynamic Low-Rank Projection: MLA adjusts the compression strength for Key/Value vectors based on sequence length.
-
Adaptive Query Compression: Adaptive scaling of the query at different layer depths. Early layers maintain expressiveness with higher-dimensional queries, while deeper layers compress more aggressively.
-
Joint KV Storage: Shared KV storage further reduces memory traffic during multi-node inference.
-
Layer-Wise Adaptive Cache: Instead of caching all past tokens for all layers, V3 prunes older KV entries at deeper layers to manage memory usage with 128K context windows.
The architecture diagram for MLA, showing the compression of queries, keys, and values using down projection matrices, is displayed below.

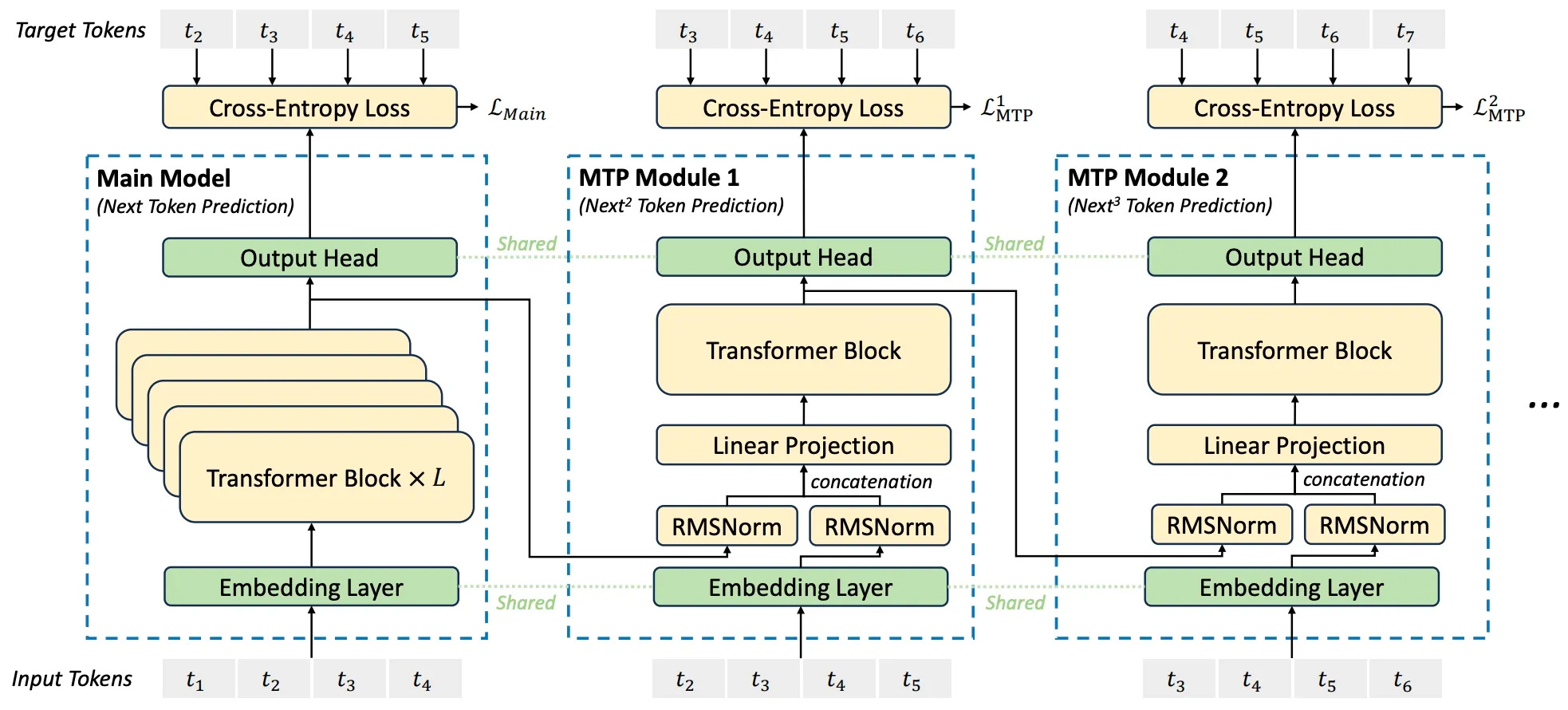
Multi-Token Prediction
The architecture was enhanced with MTP modules by the DeepSeek team to enable the model to predict multiple future tokens simultaneously. This allows for a deeper understanding of context and generation of more coherent sequences due to the model’s ability to look ahead further into the sequence. Compared to traditional single-token prediction methods, this significantly improves both efficiency and performance. The diagram below illustrates the MTP module alongside the main module.
Conclusion
This concludes this section. We explored three primary architectural patterns that the DeepSeek team adapted and enhanced to develop the DeepSeek-R1 model: DeepSeekMoE, Multi-Head Latent Attention, and Mult-Token Prediction. We also reviewed various improvements made to the training framework to accommodate the architectural changes. In the next and final post of this series, we will examine the changes made to the model training methodology.
Finally I have a shameless plug – I will be leading a panel discussion on foundation models and, ofcourse, DeepSeek-R1 at the engineering summit on March 28 at Palo Alto, California. A bunch of very enthusiastic volunteers of Founder’s Creative are organizing the event. We have a very interesting lineup of speakers and panels. If you are in the San Francisco Bay area around that time then you should take a look.
